Hadoop分布式集群搭建
写在前面
之前已经搭过Hadoop伪分布式,这次就大致说说分布式是怎么回事,其实他们也就是配置文件不一样,其他都是差不多的,但是为了更熟悉相关操作,我还是建立了三台虚拟机,从头搭起(为了更好的体验,我特地加了内存条,心疼我的钱啊)当然,搭建的方法不限于这一种,且顺序也不一定相同,我只是按自己的来
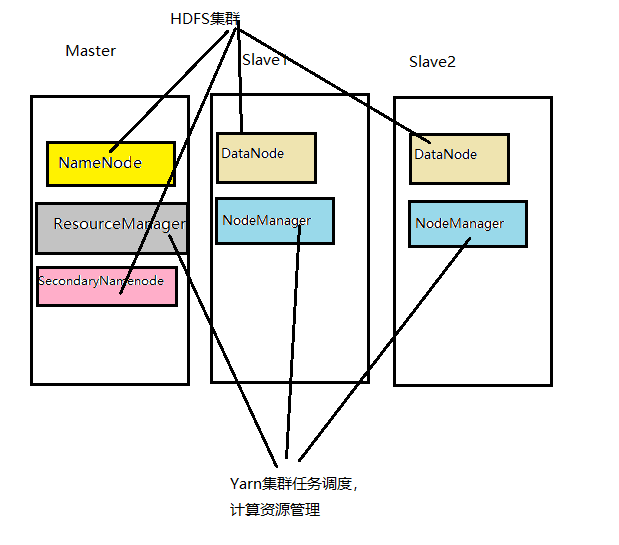
框图
其实里面很核心的一个东西HDFAS(Hadoop Distributed File System),Hadoop分布式文件系统,我们将庞大的数据存储在这。我们的主节点中有NameNode,ResourceManager,SecondaryNameNode。然后的两个slave节点中放DataNode,NodeManager.
第一步 建立虚拟机
推荐使用CentOs,真的非常好用,一开始我们就建立一个就可以了(这个就不用我再说明了),然后安装完成我们可以进行克隆,然后就得到另外两台机子,当然,我们得重新配置这两个Slave,把内存调成1G,处理器都调成1,当然,如果你的机子配置好的可怜,可以当我这是句废话。然后开机,设置成开机默认以黑窗启动,不要开图形界面,否则卡的要死。。。。
之前看某些文章说手动配置三台机子的IP,其实这个没什么必要,动态分配也是可以的,手动的话反而麻烦,如果说有什么必要性的话,目前还是学习阶段,瞎捣鼓就是要命。
然后我们用Xshell连接上三台虚拟机,这样操作实在是方便舒服。(Putty也还可以啦)
第二步 hostname设置
每台虚拟机中设置hostname
1
2
3
4
5
|
sudo vi /etc/sysconfig/network
然后编辑下列文本
NETWORKING=yes
HOSTNAME=master #master中就写master,slave1就写slave1,2就写2
#当然,你名字可以随便取,不一定像我这样master啊。。。
|
然后设置hostname与IP的映射
1
2
3
4
5
|
sudo vi /etc/hosts
然后在文本最底下添加
192.168.xxx.xxx master #IP地址是你的虚拟机的,你可以使用ifconfig查看
192.168.xxx.xxx slave1
192.168.xxx.xxx slave2
|
注意啊,如果你的hostname没改的话,去 /etc/hostname改
角色的分配
master: NameNode DataNode ResourceManager NodeManager SecondaryNameNode
slave1:DataNode NodeManager
Slave2:DataNode NodeManager
SSH 免密登录
为了省去每次登录输入密码的操作(人的本性懒)我们设置ssh免密登录
1
|
ssh-keygen -t rsa #生成key
|
然后一路回车(每个虚拟机都要生成一次)
然后你 ls -al会看到一个隐藏文件夹 .ssh,我们的key就在里面
我们进去会看到
然后我们不是确定了master为老大么,我们分别使用
1
2
3
|
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
|
将key传到本地跟另外两台机器,然后每个./ssh里面会多个 authorized_keys文件
然后你就可以使用 ssh master(或是ssh slave1或是ssh slave2登录了)
jdk安装
这个具体我就不说了,详情参照伪分布那篇文章,不过这次我是在 home中建了个app文件夹,方便我后面操作,所以环境变量配置也是要配置正确
1
2
3
4
5
|
sudo vi /etc/profile
#然后在最底下键入
export JAVA_HOME=/root/app/jdk #这里是你jdk的安装路径
export PATH=$JAVA_HOME/bin:$PATH
#保存并退出,然后source /etc/profile 生效一下
|
Hadoop安装
我将Hadoop安装包解压至我建立的app文件夹中,然后配置Hadoop环境变量
1
2
3
4
5
|
sudo vi /etc/profile
#在刚才Jdk下面键入
export HADOOP_HOME=/root/app/hadoop #这是你Hadoop的安装路径
export PATH=$HADOOP_HOME/bin:$PATH
#保存并退出,然后source /etc/profile 生效一下
|
Hadoop文件配置
hadoop-env.sh的配置
进入 cd ~/app/hadoop/etc/hadoop,然后ls会看到一大堆配置文件
先配置hadoop-env.sh,
1
2
3
|
sudo vi hadoop-env.sh
#找到 export JAVA_HOME=${JAVA_HOME}
将${java_home}改成你的java_home路径
|
core-site.xml配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
sudo vi core-site.xml
#键入配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> #这里是你的主机名
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
|
hdfs-site.xml配置
1
2
3
4
5
6
7
8
9
10
11
12
13
|
sudo vi hdfs-site.xml
#添加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
|
mapred-site.xml配置
这个文件一开始是叫做mapred-site.xml.template 模板啊。所以使用
mv mapred-site.xml.template mapred-site.xml 修改文件名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
sudo vi mapred-site.xml
#添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
|
yarn-site.xml配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
sudo vi yarn-site.xml
#添加
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
|
Slaves配置
顾名思义,这个就是将我们的slave放进去
1
2
3
4
5
6
|
sudo vi slaves
#删去原有的localhost,添加
master
slave1
slave2
|
当然这些配置hadoop官网都有说明,如果想更细节地了解,请前去看看。下面是官网对于这些配置中的参数说明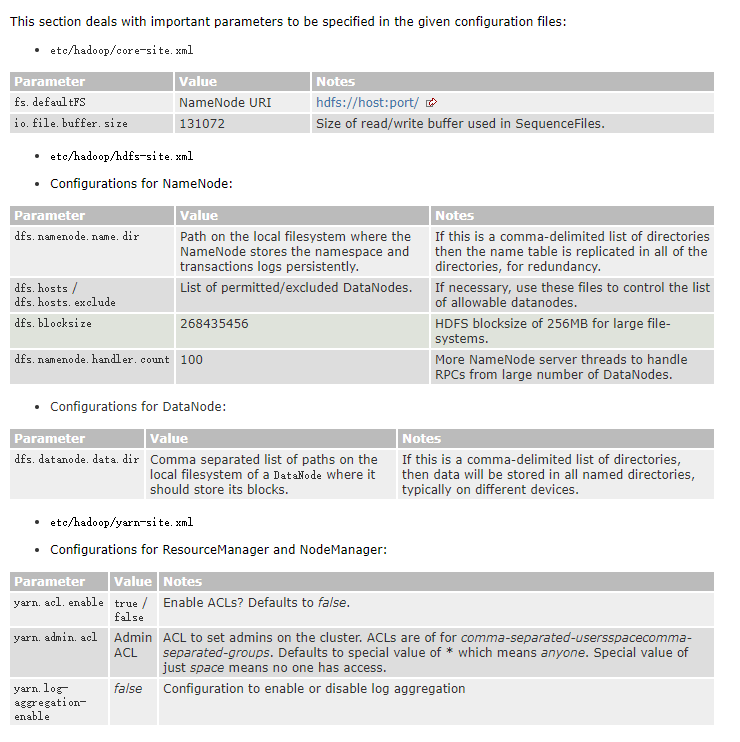

分发到另外两台机器
我们目前的配置都是在master上操作的,但是我们必须得保证每台机器都有这样的配置,所以我们需要将master上的app 分发到slave1 和slave2上(这就是我单独建立app文件夹的原因,因为我需要进行分发,所以,将hadoop,jdk都放在其中,便于打包发过去)
我们使用的命令是
1
2
3
4
5
|
scp -r ~/app hadoop@slave1:~/
#这里hadoop@slave1就是你终端前面那个东西,:后面是你分发到的文件路径,
#最好跟master一样,要不然环境变量里面路径得改
#-r是递归的意思,app中所有文件全部分发
scp -r ~/app hadoop@slave2:~/
|
当然,.bash_profile也要发的
1
2
3
|
scp ~/.bash_profile hadoop@slave1:~/
scp ~/.bash_profile hadoop@slave2:~/
#这个东西分发过去别忘了生效
|
然后就是漫长的等待
NameNode格式化
这一步在master上执行,进入 cd /app/hadoop/bin/ 然后执行
1
|
./hdfs namenode -format
|
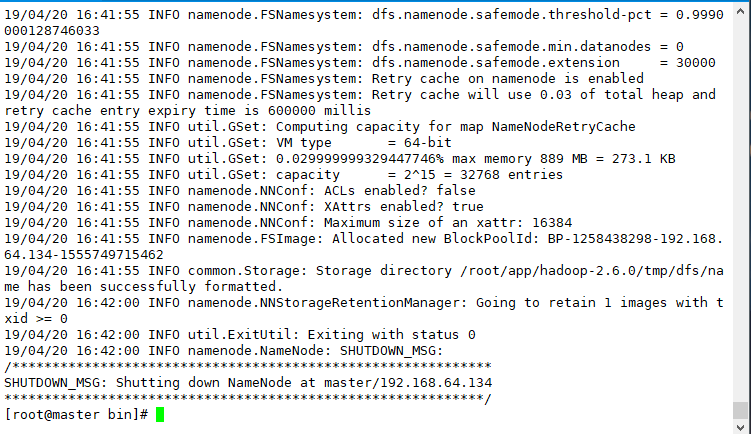
显示上图则成功
启动Hadoop
这里先关闭防火墙,systemctl stop firewalld
然后我们进入 cd /app/hadoop/sbin/ , ls查看一下sbin下有哪些文件
然后我们开始启动hadoop
1
|
./start-all.sh #启动所有,当然也可以一个一个启动
|
启动完毕我们执行jps命令,master中出现
1
2
3
4
5
|
namenode
secondarynamenode
datanode
resourcemanager
nodemanager
|
slave1中出现
slave2中出现
由此,分布式Hadoop集群搭建完毕
后话
其实如果只是学习,不是非得用分布式,与其折磨自己,还不如先用伪分布将hadoop玩玩透,其实就与分布式没差,都是一样的。
