Hadoop 用户手机流量处理1
hadoop的mapreduce一个经典入门案例就是wordcount,对单词进行词频统计,其输入输出的数据类型都是hadoop封装好了的,比如Text, IntWritable, LongWritable, NullWritable这些,但是如果是我们自定义的类型该怎么做,这就涉及到了hadoop的序列化与反序列化
序列化
什么是序列化(serialization),序列化是指将结构化对象转化为字节流,那么相反的,反序列化(deserialization)就是序列化的逆过程,将字节流转换回结构化对象。如果想在进程之间传递对象或者持久化对象时,我们就需要进行对象的序列化,如果要从接受到的或者磁盘读取的字节流转换为对象,就要反序列化。综上,序列化用于:进程间通信,持久化存储。
java的序列化在使用后,序列化的对象会附带很多额外的信息,不便于高效传输,因此hadoop自己做了一套序列化机制,也就是Writable,hadoop定义了这样的一个Writable接口,一个类如果需要支持序列化,那么只需要实现这个接口即可。
一个案例
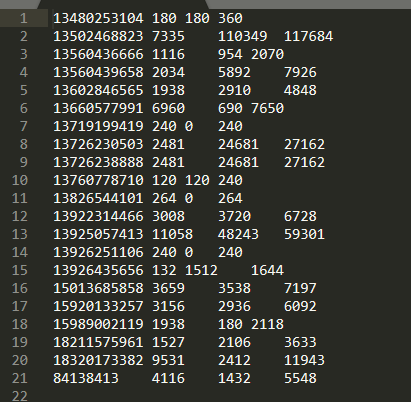
当前有一个用户手机流量数据,使用mapreduce,统计每一个用户(手机号)所耗费的上行流量,下行流量,总流量
数据的具体格式如下:
map
首先是map函数,输入的类型为LongWritable(map分区),Text(每一行的内容),根据业务逻辑可知,输出类型是Text(手机号),FlowBean(一个包含了总上行流量,总下行流量,总流量的对象)。但是hadoop并没有FlowBean这个类型,所以,这里我们就要用到前面说的hadoop的序列化机制。
新建FlowBean类,要实现Writable接口中的两个方法,一个write(序列化),一个readFields(反序列化),然后就是把这个java bean写完,具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
package com.hjj.FlowSum;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
// 只用upFlow和downFlow的构造方法,以便map中实例化对象
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow+downFlow;
}
public FlowBean(long upFlow, long downFlow, long sumFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = sumFlow;
}
// 定义一个set方法,来优化map
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow+downFlow;
}
// 序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
// 参数dataOutput的write方法来实现序列化,根据成员的类型来,因为是long所以这里就是writeLong
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
// 反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
// 这里要注意,反序列化的顺序一定要跟序列化函数一样,使用read
this .upFlow = dataInput.readLong();
this .downFlow = dataInput.readLong();
this .sumFlow = dataInput.readLong();
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}
|
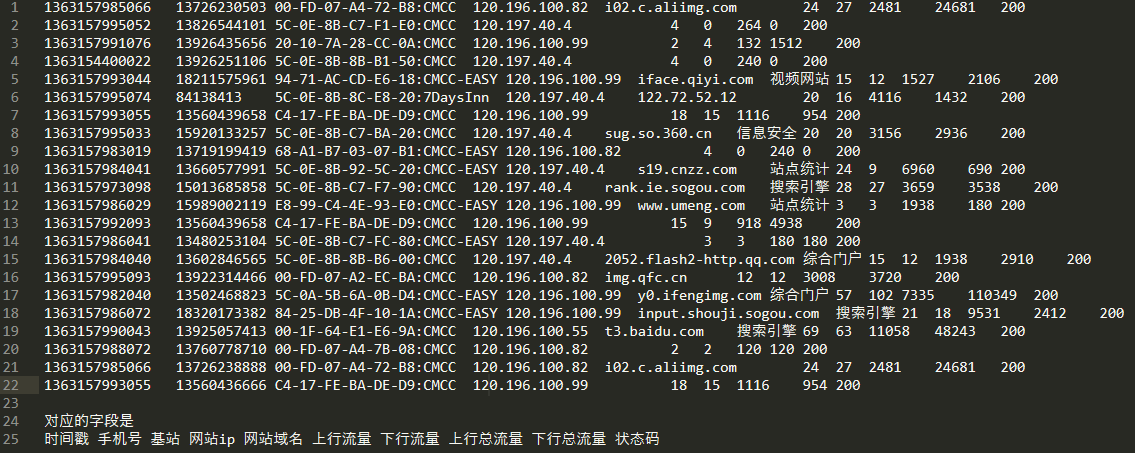
接下来就可以正式来写map方法了,现看看每个字段的特点:
1
2
|
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
|
每行定义成line,然后分隔符是制表符,所以split方法参数应该是split("\t"),这样的话就得到了一个String数组,定义成fields,那么根据我们输出的要求,手机号就是fields[1],但是问题来了,第一个正常数据,所有字段都包括了,能用 fields[7],fields[8] 代表总上行流量和总下行流量,但是第二个这种的,由于少了域名字段,就不能继续使用前者的结构了,所以需要换个思路,这里我们可以采用从后向前遍历,虽然有的数据不完整,但如果采用此方法,那么所有的总上行流量和总下行流量都可以用 fields[fields.length-3], fields[fields.length-2]来表示了。接下来就可以使用context来写入了
context.write(new Text(phoneNum),new FlowBean(upFlow,downFlow));
但是我们的FlowBean没有使用两个参数的构造方法,所以我们前面的FlowBean中还要添加一个两个参数的构造方法。前文的代码中已经添加过了。最后给出map代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package com.hjj.FlowSum;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 采用自定义类型,要实现hadoop的序列化机制,接口是Writable
*/
public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phoneNum = fields[1];
long upFlow = Long.parseLong(fields[fields.length-3]);
long downFlow = Long.parseLong(fields[fields.length-2]);
context.write(new Text(phoneNum),new FlowBean(upFlow,downFlow));
}
}
|
但是如果这么写的话,在性能上面有个问题,map每进行一次处理的时候,都会去new一个Text和FlowBean,那么如果我们数据很多的话,最终垃圾回收会影响到性能。所以我们在map方法前就定义好Text对象和FlowBean对象,然后每进行一次map处理,只需要使用set即可,而不需要再实例化对象,Text是hadoop封装的类型,可以直接使用set方法,但是FlowBean是我们自定义的类,所以我们还要再前面的FlowBean代码中添加set,前面的代码已经添加过了。所以最终map代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package com.hjj.FlowSum;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 采用自定义类型,要实现hadoop的序列化机制,接口是Writable
*/
public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
Text k = new Text();
FlowBean v = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phoneNum = fields[1];
long upFlow = Long.parseLong(fields[fields.length-3]);
long downFlow = Long.parseLong(fields[fields.length-2]);
k.set(phoneNum);
v.set(upFlow,downFlow);
context.write(k,v);
}
}
|
reduce
reduce阶段相对就简单了,定义两个计数变量用于遍历的时候累加,然后同样采用优化,在方法前就实例化对象,然后set。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package com.hjj.FlowSum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* reduce类
*/
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
FlowBean v = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
// 上下行流量遍历计数
long upFlowCount = 0;
long downFlowCount = 0;
// 遍历迭代器,使用get方法获取上下行流量
for (FlowBean bean: values){
upFlowCount += bean.getUpFlow();
downFlowCount += bean.getDownFlow();
}
// 最终set一下
v.set(upFlowCount,downFlowCount);
context.write(key,v);
}
}
|
mian方法运行
这里都是模板化的,直接给出代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package com.hjj.FlowSum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowSumDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 通过Job的静态方法getInstance()
Job job = Job.getInstance();
// 指定jar包运行主类
job.setJarByClass(FlowSumDriver.class);
// mr的mapper
job.setMapperClass(FlowMapper.class);
// mr的reducer
job.setReducerClass(FlowReducer.class);
// mr的mapper阶段输出k v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// mr的最终k v
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 数据在哪 往哪输出
FileInputFormat.setInputPaths(job,"D:\\Code\\javaCode\\data\\input");
FileOutputFormat.setOutputPath(job,new Path("D:\\Code\\javaCode\\data\\output"));
// 提交mr,并且监控打印执行情况
boolean b = job.waitForCompletion(true);
System.out.println(b?0:1);
}
}
|
这里采用local方式来测试,所以路径是本地的,也可以放到集群上。
但是当我们查看结果时,出现的这样的
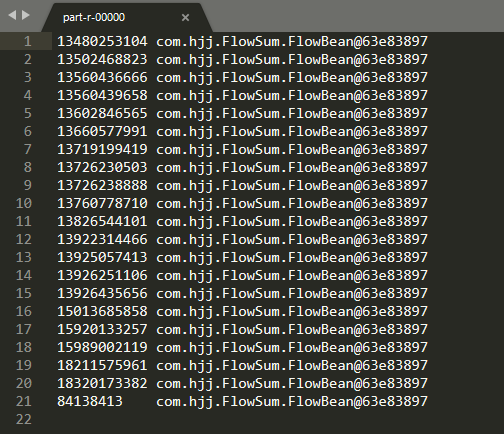
额,原来是FlowBean的toString方法忘了写,所以还要在FlowBean中添加:
1
2
3
4
|
@Override
public String toString() {
return upFlow+"\t"+downFlow+"\t"+sumFlow;
}
|
这样的话就没什么问题了