Hadoop案例笔记2
内容接上一个笔记 Hadoop案例笔记1
我们对题目进行一个扩展,在上一个案例得出的结果上将统计的结果按照总流量的倒序排序
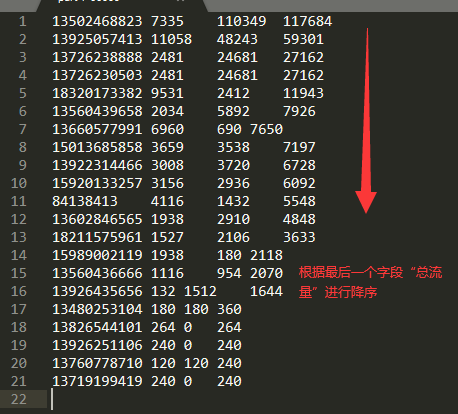
我们来看一下上一篇的结果图
结果内容分别是手机号,总上行流量,总下行流量,总流量,但是可以看到一个规律,就是结果的排序依据是按照手机号进行的,从图中可以看出134,然后135······。mapreduce默认是按照key来进行字典正序排序的
思路
既然要求按照总流量倒序排序,那么我们可以尝试将FlowBean作为key,然后重写compareTo方法,这样不就可以实现倒序排序了吗。我们当然可以继承java.lang的Comparable,但是hadoop有一个实现了 Writable 和 Comparable 接口的 WritableComparable 接口,这个接口是实现了 Writable 接口的 ,所以FlowBean可以将之前实现的 Writable 改为 WritableComparable,这样的话,排序和序列化功能两不误。
WritableComparable<> // 接口的泛型是比较大小的依据的类,比如此案例是比较FlowBean,那么这里的泛型就是FlowBean
FlowBean类
完整的代码就不贴出了,主要就是进行了几处修改。
1
2
3
4
5
6
7
|
// 第一处改为
public class FlowBean implements WritableComparable<FlowBean>
// 第二处要重写compareTo方法
@Override
public int compareTo(FlowBean o) {
return this.sumFlow > o.getSumFlow()?-1:1;
}
|
首先要将原先实现的Writable接口改为WritableComparable,这个接口实现要重写compareTo方法,compareTo 方法用于将当前对象与方法的参数进行比较,如果指定的对象与参数相等,那么返回0,如果指定的对象小于参数,返回-1,如果指定的对象大于参数,则返回1,(这个属于Java语法中的东西了)。
举个例子 s1.compareTo(s2),如果返回了1,那么s1大于s2,就是s2在s1前了,如果返回 -1,那么结果就是相反的。
现在我们重写了这个方法,修改一下逻辑就可以进行倒序了。思路是当前对象是否大于参数,如果大于我们不给他返回1了,而是返回-1,然后小于才给他返回1,这样不就是倒序了吗。
Map
map阶段的逻辑没什么差别,主要就是map的结果类型进行调换,key是FlowBean,value是手机号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package com.hjj.FlowSum;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowBeanSortMap extends Mapper<LongWritable, Text, FlowBean, Text> {
// 现在的结果类型,value是Text,key是FlowBean
Text v = new Text();
FlowBean k = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phoneNum = fields[0]; // 由于数据处理的是上一题的结果,所以第0个是手机号
long upFlow = Long.parseLong(fields[1]);
long downFlow = Long.parseLong(fields[2]);
k.set(upFlow,downFlow);
v.set(phoneNum);
context.write(k,v);
}
}
|
Reduce
由于处理的数据是上一题的结果,而且map的结果已经被compareTo排序过,key和value在 reduce这里只要做个调换就可以。
1
2
3
4
5
6
7
8
9
10
11
12
|
package com.hjj.FlowSum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowBeanSortReduce extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(values.iterator().next(),key);
}
}
|
main方法
还是模板套路
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package com.hjj.FlowSum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowBeanSortDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(FlowBeanSortDriver.class);
job.setMapperClass(FlowBeanSortMap.class);
job.setReducerClass(FlowBeanSortReduce.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job,"D:\\Code\\javaCode\\data\\input");
FileOutputFormat.setOutputPath(job, new Path("D:\\Code\\javaCode\\data\\output"));
boolean b = job.waitForCompletion(true);
System.out.println(b?0:1);
}
}
|
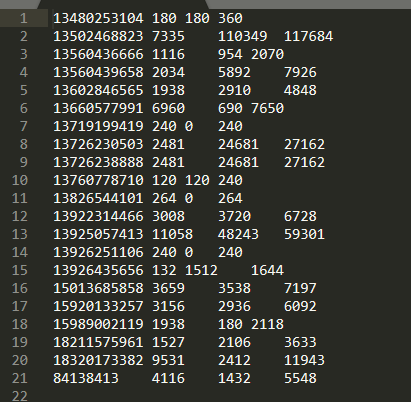
结果
最后结果就是根据总流量进行降序排序。