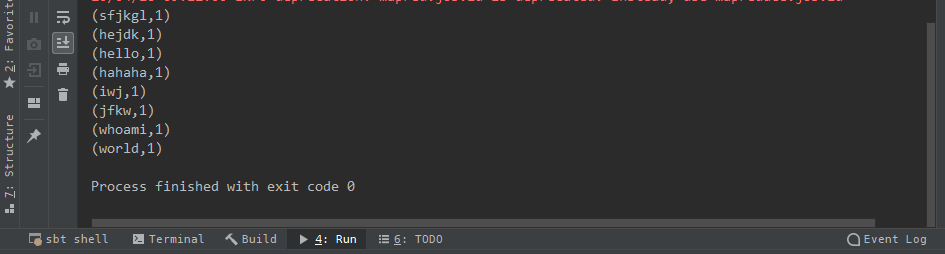
spark+IDEA示例
1
2
3
4
5
6
7
8
|
集群
master 192.168.160.21
slave1 192.168.160.22
slave2 192.168.160.23
这里用的安装包版本为
scala-2.11.8.tgz
spark-2.1.3-bin-hadoop2.7.tgz
spark安装包的选择根据你的hadoop和scala版本来,官网有详细说明
|
Spark 支持在各种集群管理器上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器。这里我们采用hadoop yarn管理,所以先决条件是hadoop集群的搭建。其次,spark是由scala编写,所以我们还要有scala的环境。
Hadoop集群搭建过程
scala安装
scala安装非常简单,同java的安装步骤一致,解压准备的安装包
1
|
tar xvf scala-2.11.8.tgz
|
然后配置环境变量,再使之生效即可
1
2
3
4
|
vim /etc/profile
添加
export SCALA_HOME=[你的scala目录]
export PATH=$SCALA_HOME/bin:$PATH
|
使用scala -version可以查看版本,说明安装成功
spark集群搭建与配置
首先解压准备的安装包
1
|
tar xvf spark-2.1.3-bin-hadoop2.7.tgz
|
然后进入spark目录下的conf文件夹中修改配置文件
1
2
3
|
conf下两个配置文件都是template结尾,我们可以cp一下
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
|
然后修改spark-env.sh,添加如下
1
2
3
4
5
|
export JAVA_HOME=[你的java目录]
export SCALA_HOME=[你的scala目录]
export SPARK_MASTER_IP=192.168.160.21 #master的ip
export SPARK_WORKER_MEMORY=1024m #worker 的内存
export HADOOP_CONF_DIR=[你的hadoop目录/etc/hadoop]
|
修改slaves,删去原本的localhost,添加
启动spark集群
首先要先启动Hadoop集群,然后再启动spark
进入spark目录下的sbin文件夹
1
|
./start-all.sh # 启动所有集群
|
启动成功后,使用jps查看进程
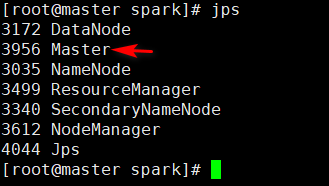
master节点上多了个master
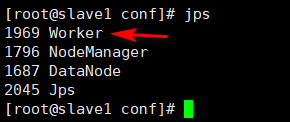
两个slave节点多了worker
然后打开192.168.160.21:8080在web界面可以查看节点情况
IDEA+sbt编程环境配置
当然你的windows环境下也要安装相应版本scala
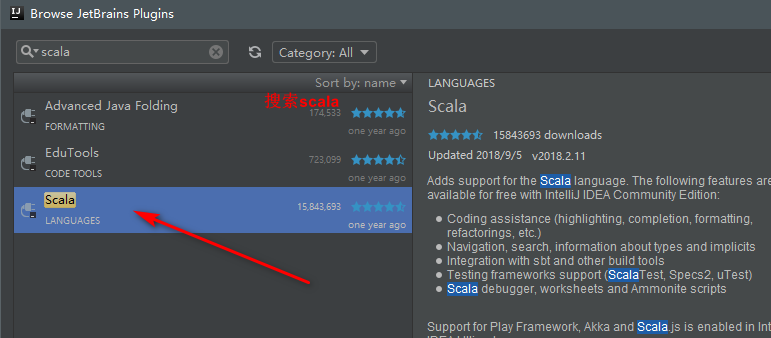
首先IDEA安装scala插件

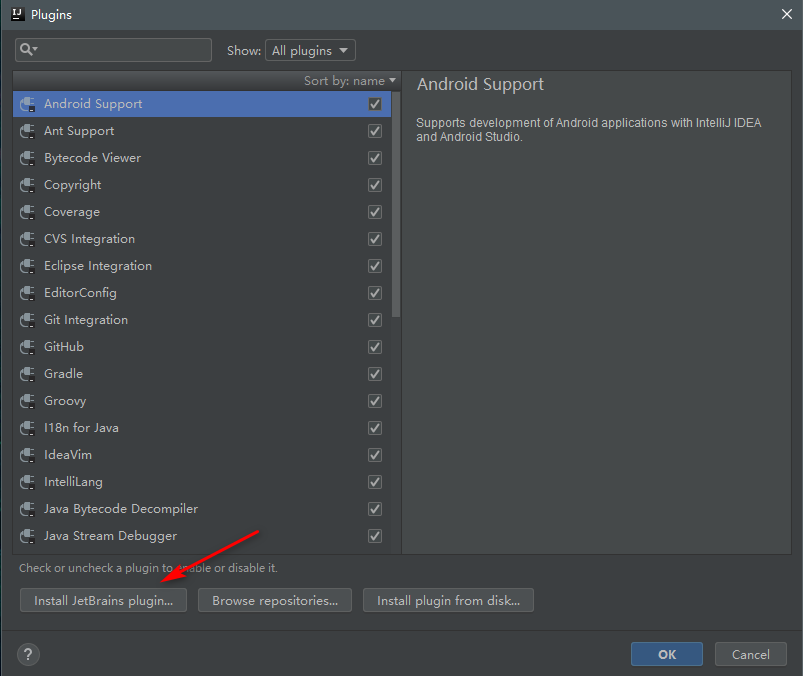
搜索scala,然后安装即可
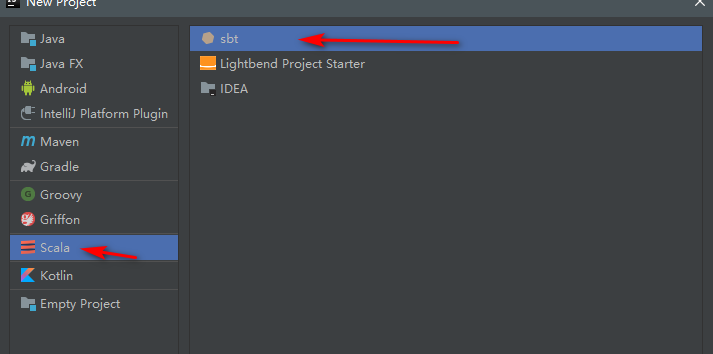
然后新建项目,选择scala->sbt,然后点击next
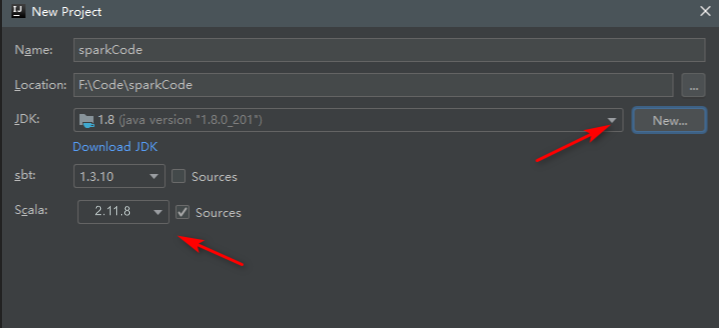
这里根据我们的scala选择版本,根据spark版本前提来,然后命个名和路径选择,jdk那里点击new,选择到你安装jdk的文件夹,然后点击finish
项目建好后,我们编辑项目中的build.sbt文件,里面默认有了name和version,还有scalaVersion,我们根据spark官网,添加
1
|
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.3"
|
然后右下角会跳出一个提示,我们点Enable-auto-import即可,然后就是漫长的等待dump project structure from sbt,这个过程非常慢,不过可以自行谷歌换成国内源。
如果dump过程没有完成,你这时是无法新建scala class的。
wordcount示例
dump完成后,我们右键项目中的src->main->scala,然后new->scala class 新建scala文件,编写代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.log4j.{Level,Logger}
object WordCount {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val inputFile = "hdfs://master:9000/input/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
|
然后右键运行,结果会显示在下方